Pytorch学习分享
安装Anaconda
安装Pytorch
使用Anaconda新建Pytorch环境,激活新环境以后安装Pytorch
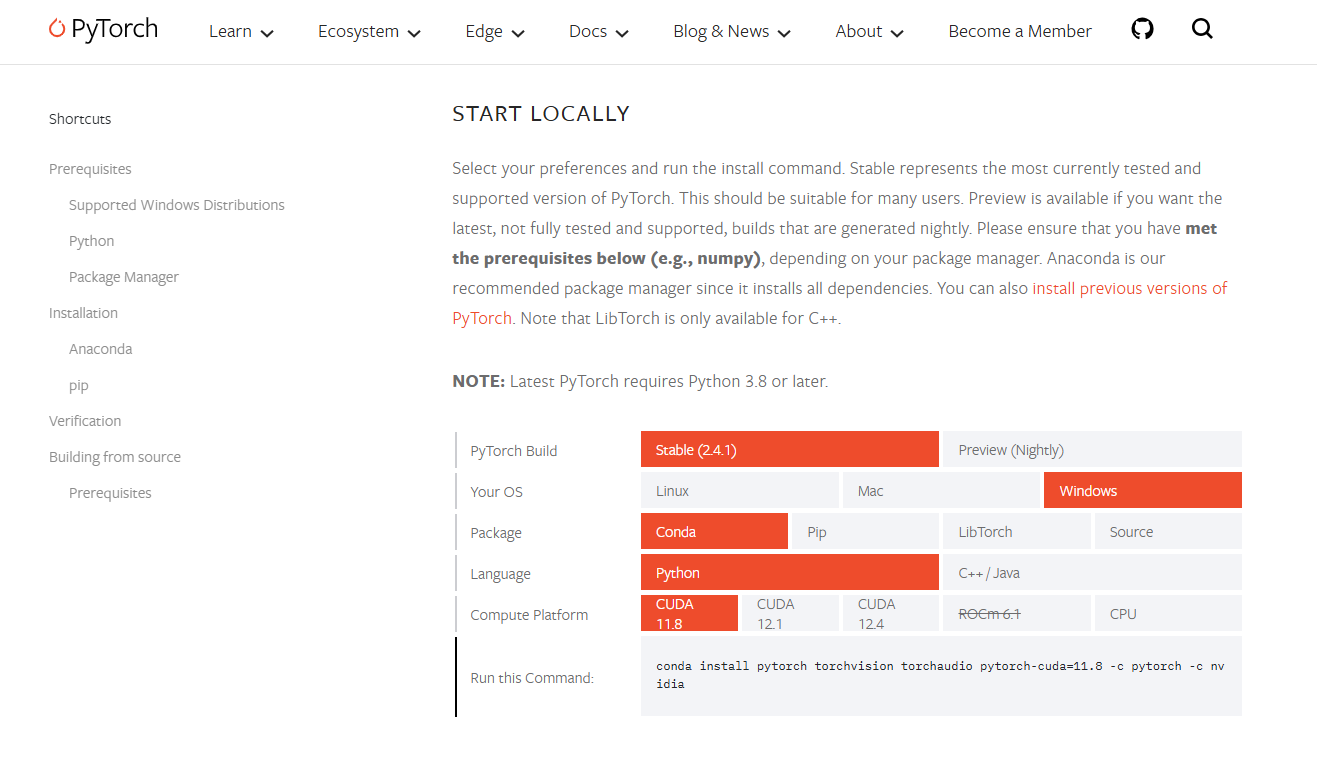
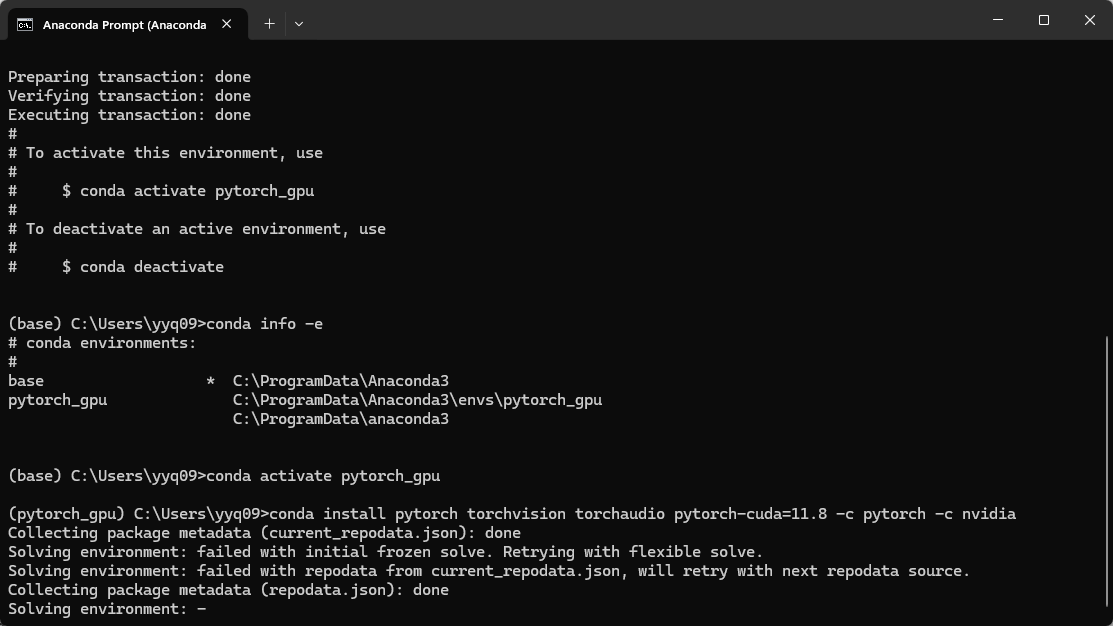
这里不要使用conda安装,否则后续的torch.cuda.is_avilable()**的返回值都是FALSE**,会出现下面的问题。需要在安装好的conda中使用pip安装,CUDA版本可以向下兼容。
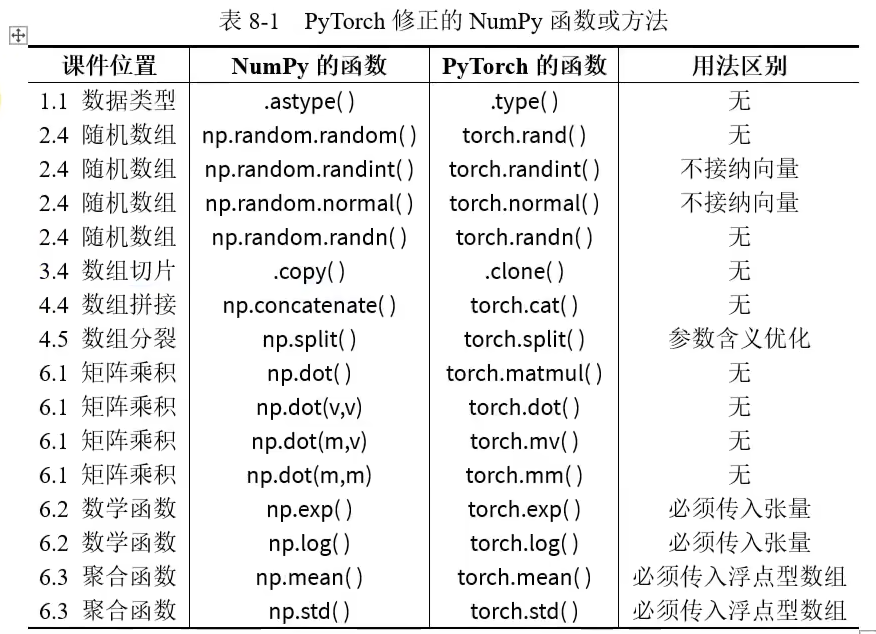
PyTorch与NumPy函数区别
大部分的PyTorch与NumPy函数是相同的,矩阵全部变为张量,部分函数的名字不同,但功能基本一致。
np 变为 torch、array 变为 tensor
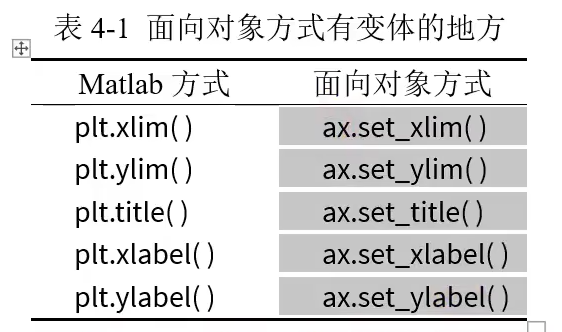
PLT使用
下面的网站有很多PLT的案例,可以替换成自己的数据以后直接使用 Examples — Matplotlib 3.9.2 documentation
使用PLT有两种方式,一种是MATLAB方式,一种是面相对象的方式。MATLAB的方式更全面,也更符合MATLAB使用的习惯。
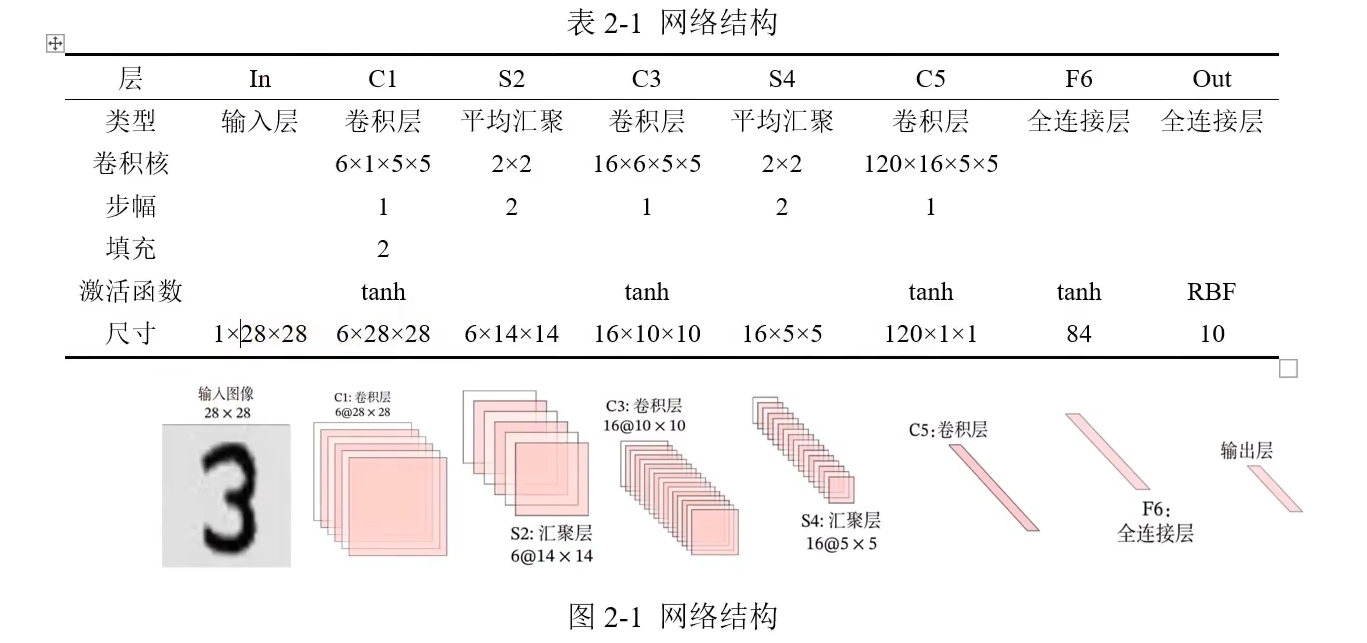
各层大小计算
卷积层:

池化层:

案例:
以下是对”PyTorch学习分享”博客的详细续写,延续原有风格并深入技术细节:
自动求导机制(Autograd)
PyTorch的核心特性是动态计算图,通过requires_grad属性实现自动微分:
1 | import torch |
计算图原理

- 叶子节点:用户创建的张量(如
x) - 运算节点:执行数学操作时创建
- 梯度计算:
backward()从根节点反向传播梯度
调试提示:使用
detach()断开计算图,with torch.no_grad():禁用梯度跟踪
损失函数与优化器
常用损失函数对比
| 函数名称 | 公式 | 适用场景 |
|---|---|---|
nn.MSELoss() |
∥y_pred - y_true∥² | 回归任务 |
nn.CrossEntropyLoss() |
-Σ y_true·log(softmax) | 多分类任务 |
nn.BCELoss() |
-[y·logŷ + (1-y)log(1-ŷ)] | 二分类任务 |
优化器选择指南
1 | from torch import optim |
重要提醒:忘记
zero_grad()会导致梯度累积,引发训练异常
模型训练完整流程
1 | # 1. 数据准备 |
模型保存与加载
正确保存方式
1 | # 保存完整模型(含结构) |
多GPU训练保存技巧
1 | # 使用DataParallel时 |
GPU加速实践
设备切换最佳实践
1 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu") |
性能优化技巧
- 数据加载:使用
pin_memory=True+non_blocking=True1
2
3loader = DataLoader(dataset, pin_memory=True, num_workers=4)
# 训练循环中:
inputs = inputs.to(device, non_blocking=True) - 混合精度训练:
1
2
3
4
5
6
7
8
9scaler = torch.cuda.amp.GradScaler()
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
学习建议
- 官方资源:
- 调试工具:
- 使用
torch.autograd.detect_anomaly()定位NaN值 - 通过
torchsummary打印模型结构:1
2from torchsummary import summary
summary(model, input_size=(1, 28, 28)) # MNIST输入尺寸
- 使用
- 可视化:
- TensorBoard集成:
from torch.utils.tensorboard import SummaryWriter - 网络结构可视化:
torchviz.make_dot(y, params=dict(model.named_parameters()))
- TensorBoard集成:
持续关注
torch.compile()等新特性,可提升训练速度30%以上!
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 52_Hertz!
 wechat
wechat alipay
alipay
相关推荐



评论